![]()
![]()
![]()
Use LEFT and RIGHT arrow keys to navigate between flashcards;
Use UP and DOWN arrow keys to flip the card;
H to show hint;
A reads text to speech;
158 Cards in this Set
- Front
- Back
|
What are the two paradigms of distributed computation? |
Shared memory Threads communicate using shared variables ("parallel computing") Message passing Threads communicate by passing messages to coordinate ("distributed computing") |
|
|
What is middleware? |
Offers a single-system view, a layer that separates applications from underlying platforms |
|
|
Why build distributed systems? (4) |
- Increasingly economical - Integrating can simplify business processes - Centralized system may not be powerful enough - Users may be mobile/distributed |
|
|
What are the goals of distributed systems? (4) |
- make remote resources accessible - distribution transparency - openness - scalability |
|
|
What is distribution transparency? Some examples? (7) |
Hiding the fact that the system is distributed - Access - Location - Migration - Relocation - Replication - Concurrency - Failure |
|
|
What three axes define a system's scalability? |
- Size - Geography - Administration |
|
|
What four factors limit scalability? |
- No machine has complete state info - Making decisions solely on local info - Failure of one machine doesn't break system - No implicit assumption of a global clock |
|
|
What are some fallacies of networked and distributed computing? (8) |
- Network is reliable - Latency is zero - Bandwidth is infinite - Network is secure - Topology doesn't change - One admin - Transport cost is 0 - Network is homogeneous |
|
|
What is cluster computing? Example? |
Distributes CPU or I/O-intensive jobs across multiple servers Hadoop, Spark |
|
|
What are TP (transaction processing) systems? |
Distributed transactions coordinated by TP monitor Nested transactions contain subtransactions, complicating atomic transaction commitment |
|
|
What are EAI (enterprise application integration) systems? Example? |
Integration framework forming a middleware to enable integration of systems and applications across an enterprise E-commerce |
|
|
What are pervasive systems? |
IOT |
|
|
What are sensor networks? |
Rely heavily on in-network data processing to reduce communication costs. Each sensor can process/store data, send only answers back. Ex: Smart irrigation |
|
|
What are the 4 common distributed software architectural styles? |
- Layered: control flows from layer to layer requests flow down the hierarchy and responses flow up - Object-based: Loosely organized in object-based arch, APIs like Java remote method invocation (RMI) allow remote object references and method calls - Data-centered: Communicate by accessing shared data repo, often used by web apps - Event-based: propagating events with publish/subscribe systems |
|
|
What is a common application layering strategy? |
3 layers 2. Processing or application 3. Data(base) |
|
|
Horizontal vs Vertical distribution? |
Vertical - Logical layers of system organized as separate physical tiers (separate machines for application server/database) Horizontal - One logical layer split across multiple machines (sharding) |
|
|
What are P2P systems based on?
|
Horizontal distribution Organize processes in overlay network that defines set of communication channels Churn |
|
|
How does BitTorrent work? |
Use client-server arch to provide client nodes with tracker info from server Use P2P to exchange data with nodes |
|
|
How do lightweight processes work? |
Share address space and file descriptors, allow communication between threads executing in same process. |
|
|
How do dispatcher/worker threads work? |
Dispatcher thread receives requests form network, feeds them to worker threads |
|
|
How does virtualization improve portability? |
Isolates applications from underlying hardware platform (and sometime OS) - reduces capital/operating costs by consolidating servers - enables load balancing / proactive maintenance |
|
|
What are the three tiers that clustered servers are often organized into? |
1. Logical switch: load balancer 2. Application/compute servers: heavy lifting 3. Distributed file/database: data |
|
|
What are the 7 layers of the Open Systems Interconnection (OSI) model? |
1. Physical: transmission and reception of raw bit stream over physical medium. Cables, hubs. 2. Data link: Data frames from one node to another over physical layer. Frames, envelopes. 3. Network: Controls operations of subnet, chooses paths. Packets, IP. 4. Transport: Ensures messages delivered error-free, in sequence, no loss/dup. TCP, UDP. 5. Session: Session establishment between processes on different stations. Logical ports. 6. Presentation: Formats data to be presented to application, "translator". Syntax layer, [en,de]cryption. 7. Application: Serves window for users and app processes. End user layer, user applications. |
|
|
What is the lifecycle of connection between a client and server using sockets? (7) |
1. Server and client create sockets 2. Server binds local address to socket 3. Server listens 4. Client tries to connect 5. Server accepts connection 6. Server/client send and receive 7. Server/client close connection |
|
|
What is an RPC? |
Transient communication abstraction, similar to conventional procedure call passing parameters on the stack |
|
|
What are the steps of an RPC? (10) |
1. Client process invokes client stub 2. Client stub builds message and passes to OS 3. Client's OS sends message to server's OS 4. Server's OS delivers message to server stub 5. Server stub unpacks and invokes handler 6. Handler does work and returns result to stub 7. Stub packs result into message, passes to OS 8. Server's OS sends message to client's OS 9. Client's OS delivers message to client stub 10. Stub unpacks result, sends to client process |
|
|
What is important to keep in mind when packing/unpacking messages for an RPC? |
Endian-ness. Data types of parameters must be known to unmarshall parameter values correctly (e.g. endianness doesn't apply to strings) |
|
|
What is used to define the signature of an RPC? What does it entail? |
Interface Definition Language (IDL), compiled into stubs High-level format of protocol messages for a given RPC, including parameter ordering, size, binary format, endianness, etc |
|
|
Synchronous vs Asynchronous RPC |
Synchronous: client waits for return value Asynchronous: client resumes as soon as server acknowledges receipt of request. Second async RPC can be issued by server to return result back to client |
|
|
What is a one-way RPC? |
Async RPC where a client doesn't wait for any acknowledgement from server |
|
|
What are the pros (3) and cons (4) of RPCs? |
Pros: - Simple and intuitive IPC mechanism - Clients/servers can be in different languages - Lots of open-source implementations Cons: - IDL usually supports limited data types - Client/server must both be running for an RPC - Client/server must both use same RPC - If server crashes, client stub generates error but doesn't know whether service handler was ever invoked |
|
|
What is the benefit of using a message queueing model over RPCs? |
Persists sent messages until they're consumed by a receiver, allowing sender to send even when receiver is not running |
|
|
What is contained in the basic interface of a message queue? (4) |
- Put: self-explanitory (I'd hope) - Get: blocks until specified queue is nonempty - Poll: non-blocking check of queue - Notify: handler when a specified queue receives |
|
|
Disadvantage of a message queue? |
Loose coupling cannot guarantee delivery of the message, since receipt depends on the receiver |
|
|
What does the Thrift network stack look like? |
Server (single-threaded, event-driven, etc) Processor (compiler generated) Protocol (JSON, compact, etc) Transport (raw TCP, HTTP, etc) |
|
|
What are two transparency principles broken by Thrift? |
Location transparency Thrift clients must know host/port for a given service Access transparency Thrift objects may throw variety of exceptions related to IPC |
|
|
How does TSimpleServer work? |
Single thread and blocking I/O |
|
|
How does TNonblockingServer work? |
Single thread and non-blocking I/O Can handle parallel connections but executes request serially |
|
|
How does THsHaServer work? |
One thread for network I/O and a pool of worker threads Can process multiple requests in parallel |
|
|
How does TThreadedSelectorServer work? |
Pool of threads for network I/O and pool of worker threads for request processing |
|
|
How does TThreadPoolServer work? |
One thread to accept connections, handles each connection using a dedicated thread drawn from pool of worker threads |
|
|
What are some middleware layer protocols supplied by Thrift? (3) |
TBinaryProtocol Encodes numeric values in binary TCompactProtocol Similar to TBinaryProtocol, but more compact, using variable-length encoding for ints TJSONProtocol Human-readable JSON |
|
|
What rules must be followed to provide compatibility between old and new app protocols using Thrift? (4) |
1. Manually assigned numeric tags of existing fields should never change 2. New fields can be added as long as they are optional and have default values 3. Fields that are no longer needed can be removed as long as tag numbers aren't reused 4. Default values can be changed |
|
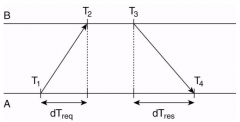
What is the formula for NTP offset? |
\theta = ((T2-T1) + (T3-T4))/2 |
|
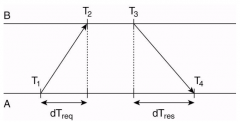
What is the formula for NTP (one-way) delay? |
\delta = ((T4-T1) - (T3-T2))/2 |
|
|
How does NTP use offsets and delays? |
Collects multiple offset-delay pairs, and then uses minimum delay as best estimate of delay. |
|
|
How do stratum levels factor into NTP clock adjustments? |
When a host contacts another, it will only adjust its time if its own stratum level is higher If it does adjust, its stratum level becomes one higher |
|
|
What relation do Lamport Clocks stress? How does it work? |
"Happens-before" relation If a and b are events in the same process, and a occurs before b, then a->b is true If a is the event of a message being sent by one process, and b is the event of the message being received by another process, then a->b is also true. Events a and b are concurrent if neither a->b nor b->a. |
|
|
What is the Lamport clock update algorithm? |
1. Process increments own counter 2. Attaches incremented timestamp to message and sends to another process 3. Receiving process sets own counter to max{timestamp, own clock} 4. Receiving process increments own counter |
|
|
What properties do vector clocks hold? (2) |
1. VC_i[i] is the local logical clock at process P_i 2. VC_i[j] = k represents P_i's knowledge of the local time at P_j |
|
|
What is the vector clock update algorithm? |
1. Process P_i increments its own counter 2. P_i sends message to P_j with incremented counter timestamp 3. P_j adjusts own vector by setting VC_j[k] = max{VC_j[k], timestamp} for each k, and then increments own counter |
|
|
What constitutes one event "happening before" another with a vector clock? |
Event i happens before event j if: VC_i[k] <= VC_j[k] for all k, and VC_i[k'] < VC_j[k'] for at least one k' |
|
|
What are the correctness properties for protocols/algorithms (according to this course)? (2) |
Safety property Must be satisfied at all times Absence of undesirable behaviour Liveness property Must be satisfied eventually Desirable behaviour |
|
|
What are the properties and assumptions required for mutual exclusion? (3, 1) |
Mutual exclusion (safety) At most one process in CS at any time Livelock freedom (liveness) If any process tries to enter the CS then eventually some process is in the CS Starvation freedom (liveness) If any process tires to enter the CS then eventually that process gets in Assumption: If a process enters the CS, it will eventually leave |
|
|
What messages are sent in a centralized mutual exclusion algorithm with a coordinator? |
By the process - Request - Release By the coordinator - OK (would be delayed if queued) |
|
|
What are the advantages (3) and disadvantages (2) to a centralized mutual exclusion algorithm with a coordinator? |
Advantages - simple conceptually - guarantees ME - starvation-free Disadvantages - coordinator must be designated ahead of time - coordinator crash breaks algorithm (one point of failure) |
|
|
How does a decentralized mutual exclusion algorithm work? |
1. If receiver is not in CS and is not trying to enter, send OK 2. If receiver is already in CS, don't reply but queue locally and send OK when leaving 3. If receiver is trying to enter, compare timestamp: b) If self has higher timestamp, send OK |
|
|
What are the advantages (3) and disadvantages (2) to a decentralized mutual exclusion algorithm? |
Advantages - guarantees ME - starvation-free - no coordinator Disadvantages - each process must know all other particiopants - crash of any process can break algorithm (multiple points of failure) |
|
|
Centralized vs decentralized mutual exclusion algorithms wrt. message and message delay complexities? |
Messages Centralized: 3K Decentralized: K(2N-1) Message delay Centralized: 1 + 2K Decentralized: 1 + K |
|
|
What are the properties and assumptions required for the leader election (bully) problem? (3, 3) |
Leader election (safety) Always at most one leader Termination (liveness) Eventually some process wins and every other process loses Leader discovery (liveness) If a process doesn't win it eventually learns ID of the winner Assumptions - initiated by exactly one process - each process either participates until eliminated or is DOA and doesn't participate - delivery/processing is timely, so not receiving a reply indicates DOA |
|
|
How does the leader election (bully) algorithm work? |
For one round of elimination: 1. Process P sends ELECTION message to all processes with higher ID's 2. If no-one responds, P wins and sends COORDINATOR message to all others 3. If process with higher ID responds, P is eliminated. Termination upon receiving COORDINATOR message. |
|
|
Remote access model vs Upload/download model for accessing remote files? |
Remote access Requests from client to access remote file, which stays on server Upload/download File moved to client, accesses done on client, file returned to server |
|
|
How does a network file system (NFS) try to handle accessing remote files? |
Supports client-side caching Flushes modifications back to server when client closes file Handles consistency in implementation-dependent way |
|
|
How does NFSv4 work? |
1. Client asks for file 2. Server delegates authority over a file to the client (which client makes local copy of) 3. Server recalls delegation 4. Client returns updated file |
|
|
What is something that NFSv4 supports over NFS? |
Compound procedures E.g. LOOKUP - OPEN - READ all in one RPC |
|
|
What's the catch to accessing nested directories exported by an NFS server? |
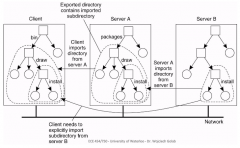
A client needs to explicitly import the subdirectory from its original server (even if it's importing a larger directory from another server which imported from the original server) |
|
|
What does striping do? |
Distributes files across multiple servers such that parts of the file are broken up amongst multiple servers |
|
|
How does the Google File System (GFS) work (access)? |
0. Master stores meta-data about files and chunks. Periodically polls chunk servers to keep meta-data consistent. 1. GFS client queries master with file name and chunk index 2. Master replies with contact address 3. GFS client queries chunk server with the chunk ID and range at the specified contact address 4. Chunk server interacts with Linux file system layered below and returns chunk data to GFS client |
|
|
How does the Google File System (GFS) work (update)? |
1. GFS client queries master for contact address of nearest chunk server 2. Master returns address 3. Client pushes updates to nearest chunk server holding the data 4. Servers pipeline update through the rest of the servers 5. Client contacts primary chunk server, which assigns a sequence number 6. Primary chunk server passes sequence number to secondary chunk servers 7. OK from secondary chunk servers to primary chunk server 8. OK from primary chunk server to client |
|
|
What are some different semantics of file sharing in a DFS? (4) |
UNIX semantics Every operation on a file is instantly visible to all processes Session semantics No changes visible to other processes until file closed Immutable files No updates possible; simplifies sharing/replication Transactions All changes occur atomically |
|
|
What type of file sharing semantics does NFSv4 support? |
Session semantics (no changes visible to other processes until file closed) + byte range file locking |
|
|
What type of file sharing semantics does HDFS support? |
Immutable files, but supports append function for storing log-structured data |
|
|
What must pillars are MapReduce based on? (3) |
- Components are not allowed to share data arbitrarily - Data elements in MapReduce are immutable. Can only communicate by generating new outputs. - Transforms lists of input data into lists of output data, usually twice: once during map and once during reduce |
|
|
What are the steps involved in MapReduce? (8) |
1. Split input from some InputFormat 2. Record readers loads data and creates key-value pairs 3. Map creates intermediate pairs 4. Combiner aggregates across all pairs generated from one map, usually identical to reducer 5. Partitioner shuffles pairs between nodes 6. Sort intermediate pairs 7. Reduce pairs to final pairs 8. RecordWriter writes pairs in some OutputFormat to file |
|
|
How does Hadoop achieve fault tolerance? |
- Primarily by restarting tasks - If job is still mapping, all other task nodes asked to re-execute all map tasks previously run by failed task node - If job is reducing, other task nodes re-execute all reduce tasks that were in progress on failed task node |
|
|
What are stragglers re: Hadoop? |
A few slow nodes that rate-limit the rest of the program |
|
|
What is speculative execution? |
When Hadoop schedules redundant copies of the remaining tasks across several nodes which do not have other work to perform - Tasks don't know where their input comes from - Therefore same input can be processed multiple times in parallel |
|
|
Why must mappers/reducers be side-effect free? |
If they had individual identities and communicated with each other / the outside world, restarting a task couldn't happen in isolation (other tasks would need to reestablish their own intermediate state) |
|
|
What does selection do re: MapReduce? |
Returns a subset of input elements that satisfy a predicate.
|
|
|
What does projection do re: MapReduce? |
Returns a subset of fields for each input element. Requires a mapper, reducer only needed to de-dupe |
|
|
What does inverted indexing do re: MapReduce? |
Given text documents, produce mapping from term to document ID |
|
|
What is cross-correlation re: MapReduce? |
Given a set of tuples, for each possible pair of items, calculate the number of tuples where the items co-occur |
|
|
Stripes vs Pairs re: cross-correlation? |
Pairs Simpler, but slower Stripes Faster, but more complex and requires more memory for map-side aggregation |
|
|
What is an RDD? |
(Resilient Distributed Data Set) Basic abstraction in Spark Represents immutable, partitioned collection of elements that can be operated in parallel |
|
|
What are transformations re: Spark? Examples? |
Data operations that convert one RDD (or pair of RDD's) into another RDD E.g. map, filter, flatMap, groupByKey, reduceByKey, union, join, sort, partitionBy |
|
|
What are actions re: Spark? Examples? |
Data operations that convert an RDD into an output E.g. count, collect, reduce, lookup, save |
|
|
What are stages re: Spark? |
Collection of transformations with narrow dependencies, defined at the boundaries with with wide dependencies |
|
|
What are narrow dependencies re: Spark? Examples? |
One partition of the output depends on only one partition of each input E.g. map, filter, union, join (inputs co-partitioned) |
|
|
What are wide dependencies re: Spark? Examples? |
One partition of the output depends on multiple partitions of some input, requiring a shuffle E.g. groupByKey, join (inputs not co-partitioned) |
|
|
What are two weaknesses of implementing PageRank with Hadoop? |
1. Intermediate output is dumped to HDFS after each iteration because it needs separate MapReduce jobs (unnecessary I/O) 2. More MapReduce jobs spawned in each iteration if testing for convergence in order to terminate the loop |
|
|
Transient vs persistent communication? |
Transient Message only delivered if both sender and recipient are up and running Persistent Message stored until recipient can receive |
|
|
Runtime system vs virtual machine monitor? |
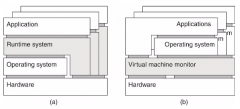
Runtime system Runs on top of OS and hardware |
|
|
NTP? |
Network time protocol |
|
|
Roman calendar? |
- 10 months |
|
|
Julian calendar? |
- Leap year every 3 years (and then 4) |
|
|
Gregorian calendar? |
- Today's leap year rules |
|
|
Solar day? |
Time difference between 2 consecutive transits of the sun
|
|
|
TAI (temps atomique international)? |
International time scale based on average of multiple Celsius 133 clocks |
|
|
UTC (Universal Coordinated Time)? |
Based on TAI Uses leap seconds |
|
|
Clock skew? |
Comparison of clock speed difference (derivative != 1) |
|
|
Clock offset? |
Comparison of clock offset (no skew) |
|
|
Maximum drift rate (re: clocks)? |
Some constant p such that derivative only drifts from 1 (perfect clock) by at most p |
|
|
What's a problem with using PageRank on graphs with disconnected components? |
Though PageRank can accurately represent importance of each page within a component, but don't reflect relative importance between components. |
|
|
Why might we want to make PageRank matrix A positive and column-stochastic? |
So that we can guarantee convergence Teleporting - blend A with an n×n positive column-stochastic matrix using a damping factor |
|
|
What is maintained in each state of a Pregel solution? |
- Problem-specific value (e.g., the PageRank of a vertex) - List of messages sent to the vertex - List of outgoing edges - Binary active/inactive state |
|
|
What model (proposed by Leslie Valiant) does Pregel use? |
Bulk Synchronous Parallel (BSP) The computation is organized into synchronous rounds or iterations, called supersteps, driven by the master |
|
|
Who decides vertex ownership when partitioning vertices within a Pregel solution? |
A partitioner, i.e. simple hash over vertices NOT determined by input splits |
|
|
How does fault tolerance in a Pregel solution work? |
- Save state before each superstep (messages, vertex/edge/aggregator values) - If >=1 workers fail, roll back all to most recent checkpoint and repeat computation - Possible to only roll back failed worker, but requires deterministic replay of messages |
|
|
Pregel aggregators vs combiners? |
Combiners - applicable when function at vertex is communicative and associative Aggregators - aggregate values at each superstep, put into tree, and root sent to master to be shared with all other vertices for next superstep - often used to test for convergence |
|
|
Why should we replicate data? (3) |
- Increase reliability - Increase throughput - Decrease latency |
|
|
When is a data store sequentially consistent? |
When the the RW order of all processes together can be broken down into each process and the ordering of the operations within each process still hold. |
|
|
When is a data store causally consistent? |
Writes related by "causally proceeds" are seen by all processes in the same order |
|
|
In what cases would Op1 causally proceed Op2? |
1. Op1occurs before Op2 in the same process 2. Op2 reads a value written by Op1 |
|
|
When is a data store linearizable? |
The result of any execution is the same as if the operations by all processes on the data store were executed in some sequential order that extends Lamport's "happens before" relation |
|
|
What are two session guarantees re: eventual consistency? |
Monotonic reads If you read value x, any successive reads on the same process will return x or a more recent value Reading your own writes A write on x will always be seen by a successive read of x on that process |
|
|
How do you determine if what determines "happens-before" relationship re: linearizability? |
Op1 happens before Op2 iff they do not overlap and Op1 finishes before Op2 starts. |
|
|
What is a way to determine linearizability using graphs? |
1. Add nodes for every operation 2. Add edges for every happens-before, reads-from, and other constraint between operations 3. If there is a cycle, the set of operations is not linearizable. |
|
|
Local-write vs Remote-write re: primary-based replication? |
Remote-write Primary is stationary, must be updated remotely by other servers Local-write Primary migrates from server to server, so updates can happen locally |
|
|
What are the rules for overlap re: strict quorum-based protocols? (2) |
Read-write conflicts 1. Nw + Nr > N Write-write conflicts 2. Nw + Nw > N |
|
|
What is the rule for overlap re: eventually consistent quorum-based protocols? What is another word for this quorum? |
Nw + Nr <= N PARTIAL QUORUM |
|
|
How do you resolve write-write conflicts with partial quorums? |
Timestamp writes and set resolution policy last write wins (Use vector clocks for concurrent clocks) |
|
|
What is an anti-entropy mechanism, and how is it used? |
A mechanism that helps to update unreachable replicas later on. Replicas may periodically exchange hashes of data to detect discrepancies. Updates can be time stamped to enable determination of the latest version of a data item. Can also exchange merkle or hash trees to detect discrepencies |
|
|
Pros and cons of quorum-based protocol with lock-based concurrency? |
Pros - linearizable - can include transaction because of 2PL - tolerates failure of 1 server without needing failure detection (constraint: needs 3 replicas) Cons - every replica keeps track of locks - deadlock possible |
|
|
Pros and cons of quorum-based protocol without locks? |
Pros - eventually consistent (if anti-entropy implemented) - no locks => no deadlocks Cons - no transactions possible - relies on global clock - doesn't guarantee linearizability |
|
|
What 4 requirements are implied by fault tolerance / dependability? |
- Availability - Reliability - Safety - Maintainability |
|
|
What are 3 types of faults? |
- Transient - Intermittent - Persistent |
|
|
What are 5 types of failures? |

- Crash - Omission - Timing - Response - Arbitrary |
|
|
What are the safety properties (2) and liveness property (1) of the consensus problem? |
Safety - two calls to decide() made by correct processes never return differently - if some process calls decide(v) then some process had previously called propose(v) Liveness - if a process calls propose or decide, it eventually terminates as long as the process remains correct |
|
|
What are factors to consider in solving the consensus problem? (4) |
- Async vs sync - Communication delays - Message delivery order - Unicast vs multicast messaging |
|
|
When is it possible to reach consensus with unordered messages? |
When the processes are synchronous and the communication delay is bounded Unicast vs multicast not factored |
|
|
When is it possible to reach consensus with ordered messages? |
When the processes synchronous Delay bounded vs unbounded not factored Unicast vs multicast not factored |
|
|
When is it possible to reach consensus with asynchronous processes? |
When messages are ordered and multicast Delay bounded vs unbounded not factored |
|
|
When is it possible to reach consensus with unicast messaging? |
When the processes are synchronous Delay bounded vs unbounded not factored |
|
|
When is it possible to reach consensus with multicast messaging? |
When processes are synchronous and delay bounded OR When messages are ordered |
|
|
What are 5 RPC failure scenarios? |
- Client is unable to locate the server - Request from the client to the server is lost - Server crashes after receiving a request - Reply from the server to the client is lost - Client crashes after sending a request |
|
|
What are 4 ways you can deal with RPC failures? How many times would a message be received for each scenario? |
- Reissue request: at-least-once (may be processed > once) - Give up and report failure: at-most-once - Reissue as needed: exactly-once (very hard and slightly unreasonable to implement) - No guarantees: confusion |
|
|
Pros and cons of Zookeeper? |
Pros - slow processes cannot slow down fast ones - no deadlock - no blocking in implementations Cons - some coordination primitives are blocking - need to be able to efficiently wait for conditions |
|
|
What properties does ZK have on read/writes? |
Linearizable writes Serializable reads (may be stale) Client FIFO ordering |
|
|
How many ZK machines do you need to tolerate f failures? Why? |
2f + 1 machines Update responses are sent when majority of servers have persisted the change |
|
|
How does ZK work wrt the leader? |
- All servers have a copy of the state in memory - A leader is elected at startup - Followers service clients, all updates go through leader |
|
|
What does Paxos guarantee and what does it make a blood sacrifice of to get it? |
Guarantees safety Sacrifices liveness (sounds very metal) |
|
|
What is Paxos? |
A solution to the consensus problem in message-passing systems |
|
|
What assumptions are made in Paxos? (7) |
- No Byzantine failures - Processes are asynchronous, may fail by crashing, and may recover from failures by restarting - Processes have access to stable storage to facilitate recovery of state information on restart - Any process can send messages to any other process - Communication delays are unbounded - Messages may be lost, reordered, or duplicated, but not corrupted - Progress is guaranteed only during periods of stability |
|
|
What roles exist in Paxos? (5) |
- Leader - Proposer - Client - Acceptor - Learner |
|
|
What is the (simplified) flow of Paxos? |
1. Client initiates proposer 2. Proposer sends Prepare(N) with proposal number N to acceptors 3. If proposal number N is higher than any other proposal number seen by acceptor, Acceptors send Promise(N, {...}) along with any other previously accepted values |
|
|
What are some variations of Paxos? (5) |
Collapsed roles Single host can be proposer, acceptor, and learner Multi-Paxos Multiple instances of protocol Skipping Phase 1 In multi-Paxos the leader may execute phase 1 once to obtain promises for multiple instances of consensus. Thus, in the steady state (i.e., stable leader, no failures) only phase two must be executed to reach agreement in the next instance. Fast Paxos Use larger quorums, but can skip Phase 1 in some cases Generalized Paxos Take advantage of commutative operations (e.g. reads) |
|
|
What assumptions are made in 2PC? (4) |
- Synchronous processes - Bounded communication delays - Crash-recovery failures - Processes have access to stable storage for logging recovery information |
|
|
What happens when the coordinator crashes in 2PC? |
Participant is able to make progress as long as it received the decision from the coordinator despite the crash, or if it was able to learn the decision from another participant Can safely commit if all are READY or COMMIT, can safely abort otherwise If all participants are READY, blocks until coordinator recovers |
|
|
What happens when both the coordinator and participant crash in 2PC? |
Makes it difficult to determine if all participants are READY |
|
|
What is a recovery line re: distributed checkpoints? |
Most recent distributed snapshot, where a distributed snapshot is a collection of checkpoints such that all sends/receives for messages do not cross the line of checkpoints (called a recovery line) |
|
|
What is the domino effect re: distributed checkpoints? |
If the most recent checkpoints taken by processes do not provide a recovery line then successively earlier checkpoints must be considered |
|
|
What coordinated checkpointing algorithm ensures that a recovery line is created? |
1. Coordinator sends CHECKPOINT_REQUEST to all processes 2. Process pauses incoming messages 3. Process takes local checkpoint 4. Process acks coordinator 5. Coordinator waits for all acks 6. Coordinator sends CHECKPOINT_DONE to all processes 7. Process resumes incoming messages |
|
|
What are some distributed computing myths? (3) |
Conventional DBs don't scale Can scale up by adding mem/storage/cores Can scale out by adding replicas Transactions don't scale Not all updates need to be processed by one node (multi-master replication, partitioning, sharing) Scalability implies high latency Maybe we don't care about selling one dress shirt to two people |
|
|
What is CAP (i.e. Brewer's Conjecture?) |
It is impossible to attain all three of the following properties simultaneously in a distributed system: Consistency – clients agree on the latest state of the data Availability – clients able to execute both read-only queries and updates Partition tolerance – system continues to function if the network fails and nodes are separated into disjoint sets |
|
|
CP vs AP re: CAP-tolerance? |
In the event of a partition (P), the system must choose either consistency (C) or availability (A), and cannot provide both simultaneously CP - in event of partition, choose consistency e.g. ACID AP - in event of partition choose availability e.g. eventually consistent system |
|
|
When are AP systems (re: CAP-tolerance) preferred? |
When data is mostly accessed with get/set, no transactions Latency-sensitive, inconsistency-tolerant applications: shopping carts, news, social networking, real-time data analytics, online gaming |
|
|
What consistency models are used in CP (4) and AP (2) systems? |
CP - linearizability - serializability - sequential consistency - Nw + Nr > N AP - eventual consistency - causal consistency |
|
|
What is PACELC? |
Give a more complete portrayal of consistency trade-offs than CAP If there is a network Partition then choose between Availability and Consistency. Else choose between Latency and Consistency. |